
۴۳ کشته در حادثه ریزش معدن طلا در آفریقا
بهمن ۲۹, ۱۴۰۳
اکتشافات جدید و توسعه فعالیتهای معدنی گروه سرمایهگذاری غدیر در حوزه معدن و فولاد
بهمن ۳۰, ۱۴۰۳

گروه رسانهای پردازش- سریهای زمانی فراوانترین نوع دادههای یافت شده در فرآیندها و خطوط تولید میباشند، زیرا آنها علائمی از حسگرها و سیستمهای ابزار دقیق هستند.
برای اینکه سریهای زمانی به درستی پردازش شوند، باید با توجه به واحدهایی که تولید میشوند و مواردی که گمان میرود هویت مطمئن و ثبت شده و قابلیت ردیابی دارند در زمینه قرار بگیرند.
برای مثال، در صنعت محصولات فولادی تخت، واحد تولید شده توپ (رول) یا کلاف ورق فولاد است. هنگامی که کلاف یک فرآیند، برای مثال خط نورد گرم را طی میکند، سریهای زمانی با توجه به لحظات زمانی که کلاف فرآیند را طی میکند دارای یک آغاز و یک انتها هستند.
در پایان، متغیرهایی همانند دما، سرعت، نیروهای نورد و غیره، بخشهایی از سریهای زمانی برای هر کلاف؛ به بیان ریاضی، بردارهای “n” نمونه، با فرض نمونهگیری زمانی یکنواخت هستند.
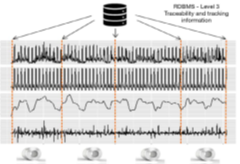
برای به دست آوردن بخشهای سری زمانی مربوط به هر محصول تولیدی (در این حالت، کلافها)، لازم است اطلاعات قابلیت ردیابی و پیگیری که در سیستمهای سطح ۳ قرار میگیرند، یکپارچه شوند، همانطورکه در شکل (۱) نشان داده شده است. اگر متغیرها که از خطوط تولید مختلف میآیند میبایستی در مجموعه دادهها یکپارچه شوند، اطلاعات قابلیت ردیابی برای فیلتر کردن مشاهداتی (کلافهایی) که یک مسیر فرآیند خاص را طی میکنند، اساسی است. طرح کلی این وضعیت در شکل (۲) نشان داده شده است.
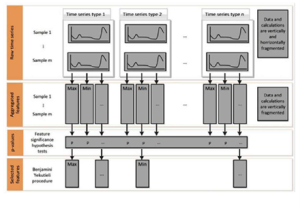
سؤال این است که چگونه متغیرهایی را که سریهای زمانی نشان میدهند در مدل گنجانده شوند. یعنی، اگر برای مورد قبلی،هر مشاهده (سطر) مجموعه دادهها با یک کلاف مطابقت داشته باشد، هر متغیر از مجموعه دادهها که نمایانگر یک سریزمانی است، متغیری است کهدارای چند مقدار است، به این معنی کهاین موردی تک مقدار نیست بلکه یک بردار از نمونهها است.از آنجا که از این طریقنمیتواندادهها را پردازش کرد،لازم است که سریهای زمانیرا با استفاده از عملگرهای (اپراتورهای) ریاضی که شناسه (آرگومان) ورودی آن یک بردار است وبه یک عامل عددی مقیاس منتج میشود، به یک پیشپردازش به نام استخراج ویژگی ارسال کرد.
تنوع زیادی از اپراتورها برای استخراج ویژگی، از سادهترین آنها (همانند میانگین، واریانس، حداکثر، حداقل) تا عملگرهای پیچیده (همانند تبدیل سریع فوریه، موجک (wavelets) و غیره) وجود دارد.
این ویژگیهای استخراج شده،به همراهسایر متغیرهای فرآیندکه ذاتاً تکمقدار هستند به متغیرهایمجموعه دادهها تبدیل میشوند. اما، از آنجا کهسریهای زمانیمعمولاً نویزی و حاوی زوائد هستند،لازم است که آنها را به فرآیند فیلتر کردن ارسال کرد تا در مورد درج آنها در مجموعه دادهها تصمیمگیری شود.
بنابراین، باید توازن بین استخراج ویژگیهای قابل توجه اما احتمالاً شکننده و ویژگیهای قوی اما احتمالاً غیرمهم حفظ شود. برخی از ویژگیها همانند میانه (median) تحتتأثیر قوی دادههای پرت (غیرعادی) قرار نمیگیرند، در حالی که برخی دیگر همانند حداکثر مقدار سریهای زمانی ذاتاً شکننده خواهند بود.
اهمیت ویژگیها برای تشخیص ناهنجاری آماری- ناهنجاری الگویی است که از رفتار مورد انتظار یا عادی انحرف دارد. بنابراین، تشخیص ناهنجاری سرنخها را بررسی مینماید و صفات را برای کشف الگوهای غیرعادی مقایسه میکند. در بسیاری از مواقع، ناهنجاریهای متعددی در گروهها، نه فقط تک اتفاقات وجود دارد.
ناهنجاریها نوعی از اختلال یا عملکرد غیرعادی یک ماشین یا فرآیند را نشان میدهند. از طرفی، تجزیه و تحلیل علامتهااز طریقتوسعه مدلهایی برایتشخیصناهنجاریها و ایجاد اخطارها و هشدارها به اپراتور، به حل این مسئله کمک میکند.
تشخیص ناهنجاری به دو قسمت تقسیم میشود: (۱) توسعه ویژگیهای مناسب و (۲) تغذیه این ویژگیها در یک مدل آماری و یادگیری ماشین که ناهنجاریهای موجود در ویژگیها را تشخیص میدهد. در صورت انجام صحیح، ناهنجاریهای تشخیص داده شده همبستگی بسیار خوبی با اختلالات در محل خواهد داشت و میتوان از آنها برای ایجاد هشدارهایی بامیزان کم مثبت کاذب استفاده کرد. ممکن است چنین به نظر برسد که پیچیدگی چنین سیستمهایی بر بخش آماری متمرکز است. اما به خوبی شناخته شده است که انتخاب ویژگی در کاربردهای واقعی مهم است.



{kind=link}
{kind=link}
{kind=link}