
📚 نگاهی به کتاب “فرایند آب در صنعت احیای مستقیم آهن”
اسفند ۱, ۱۴۰۳
بریکت سنگآهن، جایگزین گُندله در واحدهای احیای مستقیم DRI و HBI میدرکس
اسفند ۴, ۱۴۰۳
پلت فرم هاى انقلاب صنعتى چهارم، چگونه به فولادسازان براى بهبود فرآیند تولید کمک مى کند؟(قسمت چهارم)
پیشبینی خمش لبه کار انتهایی در دستگاه نورد گرم دو طرفه- در طی فرآیند نورد گرم، ضخامت اسلب تا ۹۹ درصد کاهش مییابد. در خط خاصی که این پروژه انجام شده است،بیشتر این کاهشدر یکدستگاه نورد اوليه دو طرفه ۴ غلتکی انجام میشود. در دستگاه نورد اوليه،اسلب فولادی که از کوره میآید، از مجموعهای از غلتکهای افقی و عمودی به صورت رفت و برگشتی، یعنی چند بار عبور از یک مجموعه غلتک، عبور میکند. در حین عبور اسلب در دستگاه نورد دو طرفه، گاهی عیب خمیدگی در نوکورق در حال فرآوری وجوددارد،همانطورکه در شکل(۶) مشاهده میشود.این عیب، به دلیل شکلی که ارائه میدهد، اصطلاحا به SKI یا ski معروف است. بسته به جهت و بزرگی (ارتفاع) آن،میتواند باعث شود اسلببا قاب مرحله بعدی برخورد کند یا در غلتکهای نقاله وارد شود،در نتیجه به تجهیزاتصدمه زده و باعث توقف تولید گردد.
راهکارهایی در مطالب منتشره وجود دارد که مشکل SKI را از طریق مدلسازی المان محدود و شبیهسازی، از قبیل منابع ۶ و ۷ حل کردهاند. مطابق گزارشهای آنها، ارتفاع SKI عمدتاً به تفاوت دمای بین وجه فوقانی و تحتانی ماده، اختلاف سرعت بین غلتکها، ضرایب اصطکاک بین غلتکها و ورق و همچنین اختلاف قطر بین غلتکها بستگی دارد.

برای این پروژه خاص،هدف تعیین متغیرهای فرآیندی بودکه بر وجود عیب تأثیر میگذارندو میتوانند با پیشبینی ارتفاع SKI یا بزرگی خمش لبه کار انتهایی، مشخص کنند کدام اسلبها مستعدتر به بروز SKI هستند. مجموعه دادههای ویژگیهای اولیهفرآیند شامل متغیرهایی ازمراحل مختلف فرآیند ومشخصات محصول،عمدتاکوره گرمایش و دادههای تنظیمات دستگاه نورد دو طرفه بود. یک سیستم ترموگرافی مادون قرمز (IRT)، بزرگی، جهت و زاویه SKI را که به عنوان هدف مورد استفاده قرار میگرفت، فراهم کرد.گروههای متغیر مورد استفاده برایمدلسازی عبارتنداز:روند تغییرات (پروفیل) حرارتی اسلب، غلتکها، تنظیمات دستگاه نورد دو طرفه،سرعت چرخش غلتک و مشخصات اسلب.
گردآوری جامع دادههابرای به حداقل رساندن احتمالداشتن دادههای ناکافی یا عدم توصیف کامل پدیده انجام شد. پس ازمرحله پاکسازی دادهها و مهندسی متغیرها، مشخص شد که این پدیده تنها با تعداد کمی از متغیرها قابل توضیح نیست. تجزیه و تحلیل مؤلفه اصلیبر روی دادهها انجام شد،که نشان داد۹۵ درصداز واریانس توسط۲۱ مؤلفه اصلیاز یک مجموعه دادهها با۲۲۳ متغیرتوضیح دادهشده، که ۸۵ متغیر آنها محاسبه میشوند.
مشاهدات نادرست (برای مثال، تاریخهای اشتباهناشی از عملیات دستی خط) در مجموعه دادههاقبل از مدلسازی حذفشدند.سپس مجموعه دادههابه صورت تصادفی به زیرمجموعههای آموزش و آزمون در نسبت ۸۰:۲۰، به ترتیب با ۱۲۷۸۲ و ۳۳۶۴ مشاهده تقسیم شد. سپس مشاهدات آموزش برای دادههای پرت، که از دادهها حذف شدند بررسی شدند. همراستایی نیز مورد بررسی قرار گرفت و متغیرهای با بالاترینهمراستایی برای افزایش اختلافات و بهبود قدرت پیشبینی آنها به نسبتهای مختلف تبدیل شدند.
یک متا-مدل (مدل فراگیر) از چهار مدل جداگانه بهترین عملکرد را در آزمونهای مختلف ارائه داد. چنین مدلهای منفردی عبارت بودند از: یک شبکه عصبی عمیق، یک مدل XGB ، مدل جنگل تصادفی و یک مدل درخت اضافی. سپس برای بدست آوردن پیشبینی نهایی، متوسط پیشبینی مدلهای منفرد محاسبه شد. مدلسازی با Python libraries sklearn و keras انجام شد، در حالی کهکلیه پیشپردازش دادهها در R انجام شد.
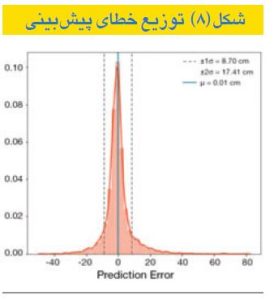
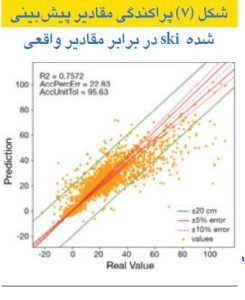
بهترین مدل دارای R۲=۰.۷۵ در مجموعه آزمون بود، ۹۵ درصد پیشبینیها دارای خطای مطلق زیر cm 20 و ۶۱ درصد خطای زیر cm 4 بودند. تابع توزیع تجمعی خطاهای مطلق در شکل(۷) نشان داده شده است. این مدل در حال حاضر اجرا میشود، با هدف پیشبینی ترکیب تنظیمات احتمالاً خطرناکی که ممکن است بهبزرگیناایمن خمش لبهکار انتهایی منجر شوند. سیستم پیشبینی بادادههای تنظیم تغذیه میشود و در صورت تشخیص چنین وضعیت ناایمنی، زنگ هشدار ایجاد خواهد شد. توزیع خطا در شکل(۸) و تابع توزیع تجمعی خطاهای مطلق در شکل(۹) نشان داده شده است.

نتیجهگیری
همانطورکه در مثالها مشاهده میشود، استفاده از تحلیلهای صنعتی برای پیشبینی رفتارهای فرآیند نه فقط یک فرمولبندی نظری که یک واقعیت است. اگر شرایط لازم برای توسعه مدلهای تحلیلی برآورده شود، یعنی در دسترس بودن دادههای تاریخی، کیفیت دادهها، بخش مرتبط متغیرهای فرآیندی ابزار دقیق فرآیند و در دسترس بودن متخصصان با تجربه در حوزه برای کار در یک تیم چند رشتهای با دانشمندان علم دادهها، امکان ایجاد ارزش از طریق نوآوریهای بر پایه تحلیلی وجود دارد.
این مسیر آسانی نیست، اما ارزش تجاری بالقوهایکه تولید میشود دلیلی بربازده سرمایهگذاری قابلتوجه است و میتواند سازمانها را قادرسازد تا استراتژیهای جدید تمایز در بازار فولاد را توسعه دهند.




{kind=link}