
مشاور عالی و دستیار ویژه وزیر صمت خبر داد: کاهش محدودیتهای انرژی واحدهای صادراتی به دستور رئیسجمهور
اردیبهشت ۶, ۱۴۰۴
ثبت بالاترین رقم سرمایه گذاری و حفاری اکتشافی ایمیدرو در سال گذشته؛ حفاری اکتشافی ایمیدرو در ۱۴۰۳ با رشد ۲۰ درصدی به ۶۷۰ هزار متر رسید/ سرمایهگذاری بیش از ۴/۵ همتی ایمیدرو برای اکتشاف معادن در ۱۴۰۳
اردیبهشت ۷, ۱۴۰۴
کنترل هوشمند نسوزها با دادهکاوی پیشرفته و یادگیری ماشین

ترجمه: محمدحسین نشاطی
ماهنامه پردازش – دیجیتالیسازی کامل صنعت، نویدبخش دستاوردهای قابل توجه بازدهی است. از زمانی که تصمیمات بر اساس دادههای قابل ردیابی اتخاذ شدهاند، این تحول شروع به تأثیرگذاری بر عملکرد کارخانههای فولادی کرده است. این مقاله رویکردی را برای کشف الگوها در مجموعههای کلان دادهها و استفاده از روشهای هوش مصنوعی (AI) برای تفسیر ارائه میکند.
برای نمونه، شناسایی مکانیزم اصلی فرسایش نسوز در مناطق گرم (هات اسپات) و بهبودهای ناشی از به کارگیری این رویکرد ارائه خواهد شد. علاوه بر این، در اینجا از این سیستم هوشمند برای بهینهسازی فرآیند برای محاسبه طول کمپین بهینه با درنظر گرفتن پارامترهای تولید، نگهداری و تعمیر (نت) و نسوز استفاده میشود. این مقاله همچنین تاثیر عملیاتی و کاربردهای آتی را مورد بحث و بررسی قرار میدهد.
صنعت ۴/۰ (انقلاب صنعتی نسل چهارم) اصطلاح رایجی برای توصیف تغییرات جاری دورنمای صنعتی، بهویژه در صنعت ساخت و تولید کشورهای توسعهیافته است. ولیاین اصطلاح هنوز هم در زمینههای مختلفی استفاده میشود و فاقد تعریف صریحی است. در این مقاله، صنعت ۴/۰ را به عنوان چهارمین انقلاب صنعتی با تمرکز بر ایجاد فرآیندهای تولید و محصولات هوشمند تعریف میکنیم.
در کارخانه فولاد آینده کهبهعنوان کارخانه هوشمند نیز درنظر گرفته میشود، سیستمهای سایبر فیزیکی (CPS) ارتباط بین انسان، ماشین و محصول را بهطور یکجا امکانپذیر خواهند کرد. مخصوصاً برای شرکتهای صنعت فولاد،ارائه محصولات سفارشی که از نظر کیفیتبرتر و از نظر قیمت رقابتی باشند، مهم خواهد بود. دستیابی به آن با اتوماسیون هوشمند و سازماندهی مجدد نیروی کار در سیستم تولید میتواند حاصل شود. عزم هرم اتوماسیون به سمت سیستمهای خودکنترلی به حجم بالایی از دادهها منتج میگردد که میتوانند استخراج، تحلیل و مصورسازی شوند. مصورسازی، قابلیت استفاده و دسترسی به دانش، محرکهای اصلی برای پذیرش کاربر هستند و نیاز به توجه ویژه در توسعه پروژههای صنعت ۴/۰ دارند.
تکنیکهای پایش وضعیت معمولاً درتجهیزات چرخنده و سایر ماشینآلات (پمپها، موتورهای الکتریکی، موتورهای احتراق داخلی، پرسها) استفاده میشوند، درحالیکه بازرسی دورهای با استفاده از تکنیکهای آزمایش غیرمخرب (NDT) و ارزیابی تناسب برای استفاده در مورد تجهیزات ثابت کارخانه مانند دیگ بخار، لولهکشی و مبدلهای حرارتی به کار میروند. امروزه، تصمیمات متناسبسازی فرآیند عمدتاً توسط انسانها بر اساس تجربه گرفته میشود. این موضوع در ارتباط با نسوز هم صادق است.در آینده،فرآیند تصمیمگیری بهطور فزایندهای توسط سیستمهای تولیدی خودبهینهساز و باهوش به این موضوع کمک خواهد کرد. در این مقاله، در مورد پایش وضعیت و تجزیه و تحلیل پیشرفته دادهها برای مخازن متالورژیکی بحث خواهیم کرد که در آن از الگوریتمهای یادگیری ماشین وروشهای پیشرفته مصورسازی دادهها برای پشتیبانی از پایگاه تصمیمگیری برای زمانبندی نگهداری و تعمیر نسوز استفاده میکنیم.

نسوزها برای مقاومت در برابر محیطهای سخت طراحی شدهاند. دماهای بیش از ℃۱۶۰۰ و فرسایش ناشی از خوردگی طول عمرمفید نسوزها را کم میکند. غیرقابل پیشبینی بودن رفتار نسوز، تطبیق چرخه عمر نسوز با چرخه عمر کارخانه را برای تولید دشوار میکند. یکی از راههای کمک به افزایش طول عمر نسوزتا برآورده کردن نیازهای عملیاتی، نگهداری و تعمیر پوشش نسوز مخزن (مثلاً با گانینگ با یک بازوی مکانیکی خودکارچنانکه در شکل (۱) نشان داده شده است) است. امروزه، چرخههای نگهداری و تعمیر بر اساس تجربه تعیین میشوند و همیشه از قبل فرسایش آینده را پیشبینی نمیکنند. بر اساس ارزیابی انسانی گاهی با پشتیبانی اندازهگیری لیزری چرخههای نگهداری و تعمیر تعیین میشوند، اما پیشبینیپذیری طول عمر پوشش نسوز اغلب رضایتبخش نیست.
رویکرد فنی
در علم داده که در آن میزان دادههای قابل دسترس در طی مدت گذشته نزدیک بهطور چشمگیری افزایش یافته است، سیستمهای هوشمند مدلسازی وابستگیهای پیچیده برای پشتیبانی از پایش فرآیندهای تولید خطرناک مانند فولادسازی توسعه یافتهاند. ما در آغاز یک دهه روند طولانی به سمت تصمیمگیری شدیدا مبتنی بر دادهها و شواهد در بسیاری از جنبههای علم و تجارت هستیم. افزایش مداوم حجم دادهها، نیازهای جدیدی مانند الگوریتمهای قابل پردازش محاسباتی را تحمیل میکند، دادههای حساس نیاز به حفاظت از موضوعات حریم خصوصی را افزایش میدهند و مقادیر زیادی از دادههای بدون برچسب (unlabeled data) نیاز به روشهای یادگیری ماشین دارند تا بهطور کامل مورد استفاده قرار گیرند.
APO بر اساس روشهایی از یادگیری ماشین و هوش مصنوعی برای تعیین وضعیت پوشش نسوز بر اساس چند منبع داده بدون هیچگونه دخالت انسانی ساخته شده است. علاوه بر این، APO فرسایش نسوز و طول عمر پوشش نسوز را پیشبینی میکند. به علاوه، تأثیر پارامترهای تولید بر فرسایش پوشش نسوز را میتوان تعیین نمود و تأثیرگذارترین پارامترها را رتبهبندی کرد. APO علاوه بر مصورسازی آمار فرآیند فولادسازی، یک پیشنهاد نگهداری و تعمیر برای بهرهبرداری بهینه از منابع نگهداری و تعمیر و عملیات پوشش نسوز را نیز استنتاج میکند.
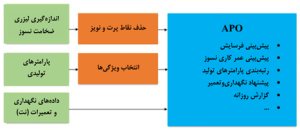
شکل (۲) مسیر پردازش دادههای APO را نشان میدهد. اکنون، APO از سه منبع داده اصلی استفاده میکند، یعنی:
اندازهگیریهای لیزری: در طی یک کمپین تولید، اندازهگیریهای لیزری برای تعیین ضخامت پوشش نسوز باقیمانده ثبت میشوند.این اندازهگیریهای لیزری مستعد نارساییهای نوری مانند گرد و غبار هستند که میتوانند منجر به مقادیری دادههای گم شده و نتایج اندازهگیری نارسا شود.ما یک مرحله پیشپردازش را برای حذف نقاط پرت، پر کردن حفرههای اندازهگیری و حذف نویز اندازهگیریهای لیزری بر اساس آمار فاصلهای مجاور محلی، برای جبران این خطاهای اندازهگیری معرفی کردیم.
پارامترهای تولید:در طی هر ذوب، چند صدپارامتر تولید همانند دما، انرژی، مدت زمان، اجزای شیمیایی و… ثبت میشود.یک مدول “انتخاب ویژگی” کهدر ادامه بیشتر مورد بحث قرار میگیرد، برای تعیین زیرمجموعهای از پارامترهای تولید که برای APO مفید هستند، معرفی میشود.
دادههای نگهداری و تعمیرات: گاهی نگهداری و تعمیرات (گانینگ، آسترزنی) برای تعمیر پوشش نسوز در مناطق با نرخ فرسایش زیاد (هات اسپات) برای افزایش طول عمر پوشش نسوز انجام میشود. در اینجا دادههای گانینگ از قبیل زمان، مخلوط گانینگ، مصرف گانینگ، نواحی نگهداری و تعمیرات، ترکیب مخلوط گانینگ در هر ناحیه به APO وارد میشود.
“انتخاب ویژگی”:در مسائل پیشبینی دنیای واقعی، ویژگیهای مربوطه (یعنی پارامترهای تولید) اغلب از پیش نامعلوم هستند. بنابراین، باید مفیدترین ویژگیها (با بالاترین محتوای اطلاعات) برای APO انتخاب شوند. “انتخاب ویژگی” برای روشهای متعدد تشخیص الگو و تحلیل دادهها مهم شده است. بسیاری از روشهای اکتشافی جستجو در جایی پیشنهاد شدهاند که جستجوی جامع معمولاً از نظر محاسباتی غیرعملی است.حتی برای یک مقدار معین از مجموعه ویژگیهای نهایی (d)،تعداد کل زیر مجموعههای مختلف
برای انجام یک جستوجوی جامع بسیار زیاد است،که در آن D تعداد کل پارامترهای تولید است. به همین دلیل، بسیاری از روشهای اکتشافی جستجوی قطعی و تصادفی غیربهینه پیشنهاد شدهاند. به ویژه روشهای جالب بر اساس الگوریتمهای ژنتیک (GA) هستند.GAها نوعی الگوریتمهای بهینهسازی هستند که بر اساس اصول تکامل طبیعی کشف شده توسط داروین بنا شدهاند. در طبیعت، آحاد موجودات مجبورند برای بقا در روند تحولات بعدی خود را با محیط خود وفق دهند. نتیجه اینکه به نظر میرسد که GAها برای مشکلات خاصی، برای مثال، کارهای جستوجو و بهینهسازی در مقیاس بزرگ رقابتی باشند.
پیشبینی فرسایش توسط APO:برای ارائه بینشهایی در مورد APO، میخواهیم بر یک رویکرد فرسایش ساده تمرکز نماییم. اندازهگیریهای لیزری پوشش نسوز برای هر ذوب به دلیل زمان مورد نیاز برای ثبت اندازهگیری در دسترس نیستند. بین دو اندازهگیری لیزری متوالی LMt و LMt+1 ضخامت فعلی پوشش نسوز را نمیدانیم. این بازه زمانی را به عنوان یک شکاف مینامیم.
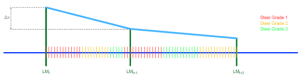
شکل (۳) طرحی از فرسایش نسوز در طی ذوبها شامل گریدهای فولادی و اندازهگیری لیزری را نشان میدهد. از یک طرف، اندازه شکافها ممکن است متفاوت باشد، از طرف دیگر، درون یک شکاف، ممکن است چند گرید مختلف فولاد تولید شوند. علاوه بر این، چند عملیات نگهداری و تعمیر ممکن است در هر شکاف رخ داده باشد (در شکل (۳) ترسیم نشدهاند).
هدف از این رویکرد پیشبینی ضخامت پوشش نسوز بر اساس گریدهای فولادی تولید شده است، با این فرض که هر گرید فولاد فرسایش منحصر به فرد خود را بر روی پوشش نسوز دارد.
رویکرد حداقل مربعات:
با توجه به تعاریف بالا، میتوان یک رویکرد خطی درجه اول ساده را فرض کرد. برای این رویکرد پیشبینی فرسایش، از روشهای حداقل مربعات استفاده میشود که در آن وزنهای wi فرسایش در هر ذوب را برای هر گرید فولاد مدل میکنند. راهحل حداقل مربعات برای [w۱ ⋯ wn+1]T سیستم معادلات زیر
را میتوان تعیین کرد که در آن∆xi فرسایش را در یک شکاف مدل میکند،GCi تعداد فرکانس گانینگ در هر شکاف را مدل میکند، SGi,j تعداد فرکانس گرید فولاد تولیدشده j بین دو اندازهگیری لیزری، n و m به ترتیب تعداد گریدهای فولاد و نمونه دادهها را نشان میدهند. هر خط از سیستم معادلات مربوط به دادههای ثبت شده هر شکاف است. در نتیجه، این رویکرد ساده تا زمانی که نویز دادهها کم باشد، عملکرد خوبی دارد. دقت پیشبینی در مورد دادههای دارای نویز کافی نیست.
به همین دلیل، این رویکرد درحالحاضر در جهات مختلف گسترش یافته است. در انجام این کار، یک زیر مجموعه از پارامترهای تولید انتخاب شدهدر مدل گنجانده شده است. علاوه بر این، این مدل توسط فیلتر کالمن (Kalman-Filter) گسترش مییابد تا انطباق پارامتر در طول کمپین را در نظر بگیرد. بعلاوه، ما یک هدف بهینهسازی ترکیبی را معرفی کردیم که دقت پیشبینی را افزایش میدهد. همچنین،یک رویکرد فرآیندهای گاوسی با استفاده از پارامترهای تولید انتخاب شده به جای گریدهای فولاد نیز بخشی از APO است.
طبق نظر Bishop و همکاران، وظیفه خوشهبندی یافتن گروههای درون مجموعهای از نقاط داده چندبعدی است. از این رو، بدیهی است که خوشهبندی یک نماینده یادگیری بدون نظارت است، زیرا دادههای ورودی که باید به گروهها تقسیم شوند،بدون برچسب هستند. با این وجود، تقسیمبندی به تعداد مشخص K زیرمجموعه، البته، به نوعی باید بهینه باشد. نوع چندبعدی نقاط ورودی (که در سراسر این مقاله به عنوان بردارهای ورودی نیز به آنها اشاره خواهیم کرد)و بنابراین معنایمختصات هر یک از نقاطبه دادههایی که قرار است خوشهبندی شوند و خود کاربرد خوشهبندی بستگی دارد. بدیهی است که یافتن بردارهای مناسب و مختصات مربوط به آنها نکته نسبتا مهمی است. از این رو، درحالحاضر، به سادگی فرض میشود که به روشی اسرارآمیز، موفق شویم N بردار ورودی چندبعدی (یا دقیقتر D-بعدی) X = {x1, …, xN} را بدست آوریم واز مجذور فاصلههای اقلیدسیبه عنوان معیارعدم تشابه استفاده کنیم. با توجه به این موضوع،میتوانیم تعریف قبلی خودازخوشه رابهطور شهودی به شکل دیگری بیانکنیم:خوشه زیرمجموعهای از X است، که در آنفاصله بین بردارهای متعلق به اینخوشه درمقایسه با بردارهای دیگر کهبه این خوشه تعلق ندارند،کوچک است.
الگوریتمهای خوشهای پیشرفتهای مانند الگوریتم خوشهبندی K-Means، که رویکردی کاملا بررسی شده و اغلب مورد استفاده است، معمولاً یکی از اولین الگوریتمهای مطرح است که وقتی صحبت از خوشهبندی دادهها از هر نوع میشود، با آن آزمایش میکنند. همانطورکهتوضیح داده شد، الگوریتم خوشهبندی K-Means بر این فرض استوار است که مادارای K بردار D-بعدی μk، به اصطلاح نمونههای اولیه [پروتوتایپ) هستیم. هر یک از این نمونههای اولیه μk با یکی از خوشههای K مرتبط است. با توجه به این موضوع، هدف این است:
(۱) اختصاص هر یک از نقاط به یکی (نزدیکترین یا بهینه) از K خوشه و
(۲) پیدا کردن مقادیر بهینه برای هر یک از K بردار نمونه اولیه μk.
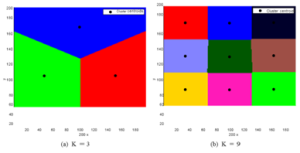
بهینه در این زمینه به این معنی است کهتخصیص نمونه اولیه حاصل وهمچنین مجموعه بردارهای نمونه اولیه {µk} باید مجموع فاصلههای مجذور بین هر نقطه و بردار نمونه اولیه اختصاص داده شده به آن را به حداقل برساند.با اعمال این قانونبهینهسازی و با توجه به استفاده از فاصلههای اقلیدسی مجذور به عنوان معیار عدمتشابه، تقسیمبندی بدست آمده “موزائیکسازی ورونی D-بعدی” نامیده میشودکه بردارهای اولیه μk را به صورتK مرکز دارد. شکل (۴) نمونهای از این موزائیکسازی را نشان میدهد که در آن ازبردارهای دوبعدی شامل مختصات x و y نقاط مربوطه در صفحه دو بعدی به عنوان بردارهای ورودی استفاده شده است.



{kind=link}
{kind=link}
{kind=link}