
رونمایی بریتانیا از برنامه سرمایهگذاری ۲/۵ میلیارد پوندی برای صنعت فولاد
بهمن ۳۰, ۱۴۰۳
حقوق دولتی معادن “قسطی” میشود
اسفند ۱, ۱۴۰۳

گروه رسانهای پردازش- در صنعت فولاد، خواص مکانیکی فولاد متمایزکنندهترین ویژگیهای اصلی در بین انواع مختلف محصولات است. خواصی از قبیل استحکام کششی، استحکام تسلیم و ازدیاد طول نسبی فولاد پارامترهای اساسی هستند در هنگام تصمیمگیری در مورد اینکه با کدام مواد در صنعت ساخت و ساز یا در صنعت خودرو کار شود. به علاوه، این خواص برای تعیین پارامترهایی که در فرآیند تولید فولاد مورد استفاده قرار میگیرند نیز به کار میروند.
خواص مکانیکی معمولاً در بخش آزمایشهای فیزیکی با نمونههای برداشته از مواد در پایان فرآیند سرد اندازهگیری میشوند.این شیوه، گرچه قابل اعتماد است، اما معایب مختلفی دارد. اول، نمونه معمولاً از یك انتهای کلاف به دست میآید، یعنی جایی كه بیشترین تغییرپذیری در شاخصهای آن، به دلیل مسائل ذاتی فرآیند پیدا میشود. دوم، خواص مکانیکی میتوانند در طول کلاف متفاوت باشند، که در حال حاضر تشخیص آن غیرممکن است. سوم، تحویل نتایج آزمایشگاهی فوری نیست، بنابراین بسیاری از محصولات انباشته میشوند؛ این باعث افزایش زمان و هزینههای تولید میگردد.
از این رو یک مدل پیشبینیکننده برای تخمین خواص مکانیکی کلاف در هنگام خروج از خط نورد سودمند و مطلوب است، زیرا امکان کار بر روی محصول در فرآیند پاییندستی واصلاح انحرافات را فراهم میکند، بنابراین از افت کلاس محصول جلوگیری میشود.
از آنجا که خواص مکانیکی به میزان زیادی به نوع فولاد بستگی دارند، مدلهای مختلفی برای سه کلاس که بر اساس ترکیب شیمیایی تقسیم میشوند تهیه شدند:
- فولاد نیوبیومدار (Nb)
- فولاد کربنی (C)
- فولاد وانادیومدار (V)
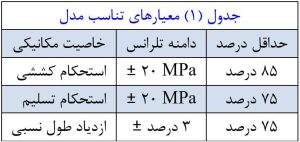
برای هر نوع فولاد، استحکام کششی، استحکام تسلیم و ازدیاد طول نسبی پیشبینی شد،بنابراین در کل ۹ مدل وجود داشت. معیارهای ارزیابی تناسب مدل همانطورکه در جدول(۱) نشان دادهشده است، یک محدوده تلرانس انحراف پیشبینی از مقدار واقعی و یک حداقل درصد که پیشبینیهای واقع شده در آن محدوده برای مدل مناسب در نظر گرفته میشوند تعیین گردید.
مجموعه دادههای مورد استفاده برای این مورد شامل دادههای فرآیندی خط نورد گرم (HRM) میباشد که دوره تقریباً ۷ ماهه تولید را در بر میگیرد و شامل متغیرهای مربوط به فرآیند (دماها، سرعتهای نوار ورق، کاهشهای سطحمقطع و غیره) و متغیرهای مربوط به ترکیب شیمیایی فولاد فرآوری شده است. هر مشاهده (سطر) کلافی را نشان میدهد که توسط HRM فرآوری شده وخواص مکانیکی آندر آزمایشگاه مشخص شده است. مشاهداتبه سه دسته توضیح دادهشده قبلی مطابق ترکیب شیمیایی فولاد تقسیم شدند.
تمام مجموعه دادهها در معرض یک فرآیند پاکسازی قرار گرفتند: متغیرهای غیرمرتبط با خواص مکانیکی شناسایی و صرفنظر شدند، همچنین متغیرهایی با نسبت بالاییاز مقادیر ناپیدا؛ پس از آن، مشاهدات بامقادیر ناپیدا یا حذف شده یا با یک مقدار دلخواه (برای مثال، ستون میانگین) بسته به ماهیت متغیرها پر میشوند. توزیع متغیرها درمجموعه دادههای حاصل برای شناسایی مقادیر پرت افتاده مورد بررسی قرار گرفت و مشخص شد که آیا آنها خطاهای اندازهگیری، خطاهای ثبت یا مقادیر واقعی را نشان میدهند و مطابق آن با آنها رفتار شد.
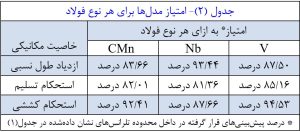
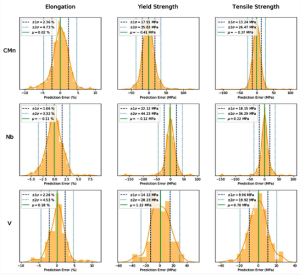
مجموعه دادهها به زیرمجموعه آموزش و زیرمجموعه آزمون تقسیم شد. برای هر نوع فولاد، یک الگوریتم یادگیری ماشین با نام Gradient Boosting Regressor برای پیشبینی هر خاصیت مکانیکی استفاده شد. این الگوریتم با زیرمجموعه پرورده شد و اعتبارسنجی گردید و سپس با استفاده از زیرمجموعه آزمون ارزیابی شد. پس از تنظیمپارامترهای الگوریتم، امتیازات حاصل از همه مدلهااز آستانههای تعیین شده پیشی گرفتند (جدول(۲) را ببینید). توزیع خطاهایپیشبینی برای هر مدل را میتوان در شکل مشاهده کرد.


{kind=link}
{kind=link}